In this post, I will introduce the DXR through porting my CPU based ray tracer into the GPU. The main goal is to implement a monte carlo path tracer with DXR on the GPU. From the post you can see that for the begining of this series, most of time is spent on the setup and the initial implementation. I will write more about the coding aspect as there are not much tutorials present on the internet. In the next posts, I will focus on missing features for a rendering engine and I want to create a rendering suite with both CPU and GPU implementations to compore and further investigate the techniques of path tracing like subsurface scattering, volumetric rendering, and more.
For the code and the project files, you can check my repository on GitHub.
Results are shown at the end of the post.
Initial Setup
For the initial setup I searched for some DXR examples online and found the Microsoft’s DXR samples, which was a good enough starting point. I picked the basic lighting sample with a cube and a light source.
The code starts by handling the necessary window operations and DirectX device initialization, this part is same with any other DirectX application (I will skip the swapchain, render target creations etc.). The main difference is the ray tracing pipeline setup and the shader creation.
In device creation there is one thing we need to add, which is ID3D12Device5 interface. This interface is necessary for ray tracing operations.
ComPtr<ID3D12Device5> m_dxrDevice;
ThrowIfFailed(device->QueryInterface(IID_PPV_ARGS(&m_dxrDevice)), L"Couldn't get DirectX Raytracing interface for the device.\n");
After creating the device we can start defining our shaders.
Defining Shaders
For a raytracing pipeline, we can define 4 new types of shaders: ray generation, closest hit, any hit and miss shaders. However, in this example we won’t use any hit shaders, even though they are useful for things like shadow rays, my implementation with closest hit shaders will be easier to understand for the beginning. We can define these shaders as below for a starting point. We will use these shaders to create our pipeline and after that we will fill them with the necessary code.
[shader("raygeneration")]
void MyRaygenShader()
{
...
}
[shader("closesthit")]
void MyClosestHitShader(inout RayPayload payload, in MyAttributes attr)
{
...
}
[shader("miss")]
void MyMissShader(inout RayPayload payload)
{
...
}
Creating the Pipeline
In the raytracing pipeline, unlike the classical pipelines, we have subobjects to define the shaders and the shader binding tables. These are useful for creating a more flexible pipeline, because we don’t need to declare every shader or every field to make raytracing pipeline start working. We can get help from DirectX12 helper library (d3dx12.h) to create our pipeline. After creating the pipeline, we will create a library to hold our shaders references which we can use later for the shader binding table.
CD3DX12_STATE_OBJECT_DESC raytracingPipeline{ D3D12_STATE_OBJECT_TYPE_RAYTRACING_PIPELINE };
auto lib = raytracingPipeline.CreateSubobject<CD3DX12_DXIL_LIBRARY_SUBOBJECT>();
D3D12_SHADER_BYTECODE libdxil = CD3DX12_SHADER_BYTECODE((void *)g_pRaytracing, ARRAYSIZE(g_pRaytracing)); // g_pRaytracing is the compiled shader code which you can compile with DXC on runtime or offline
lib->SetDXILLibrary(&libdxil);
{
lib->DefineExport(c_raygenShaderName);
lib->DefineExport(c_closestHitShaderName);
lib->DefineExport(c_missShaderName);
}
After creating the library, we can define the shader config and the hit group for the pipeline. A hit group is a combination of closest hit, any hit and intersection shaders, miss shaders won’t be in the hit groups, as they will be shared across the objects in the scene, but when we dispatch our rays, we can define which miss shader to use. In this sample I will create two different hit groups one for the diffuse materials, and other for the dielectric materials. As a further optimization, we can create a hit group for emissive materials, however in this sample I will use the diffuse hit shader for emissive materials.
//like the library, we will define the hit groups as subobjects
auto hitGroup = raytracingPipeline.CreateSubobject<CD3DX12_HIT_GROUP_SUBOBJECT>();
hitGroup->SetClosestHitShaderImport(c_closestHitShaderName);
hitGroup->SetHitGroupExport(c_hitGroupName);
hitGroup->SetHitGroupType(D3D12_HIT_GROUP_TYPE_TRIANGLES);
We also need to create the shader config, which will define the payload and attribute sizes for the shaders, here is a nice place to explain these, the payload is the data that will be passed between the shaders, like we can pass the total color values, the recursion depth, or the the distance to the hit etc. The attributes are the data that will be used for intersection data, and for the fixed-function triangle intersection we will have the barycentric coordinates of the hitpoint. For procedural primitives, we can define our own attributes and pass them with ReportHit call, which we will call with the our custom defined attributes, which can be maximum 32 bytes.
auto shaderConfig = raytracingPipeline.CreateSubobject<CD3DX12_RAYTRACING_SHADER_CONFIG_SUBOBJECT>();
UINT payloadSize = ...; // size of the custom payload
UINT attributeSize = sizeof(XMFLOAT2); // float2 barycentrics
shaderConfig->Config(payloadSize, attributeSize);
In the end we will bind our root signature to the pipeline, and create a pipeline config subobject to specify the maximum recursion depth for the raytracing pipeline.
auto globalRootSignature = raytracingPipeline.CreateSubobject<CD3DX12_GLOBAL_ROOT_SIGNATURE_SUBOBJECT>();
globalRootSignature->SetRootSignature(m_raytracingGlobalRootSignature.Get());
auto pipelineConfig = raytracingPipeline.CreateSubobject<CD3DX12_RAYTRACING_PIPELINE_CONFIG_SUBOBJECT>();
UINT maxRecursionDepth = MAX_RECURSION_DEPTH; // This field can help GPU driver to make optimizations for the recursion depth
pipelineConfig->Config(maxRecursionDepth);
ThrowIfFailed(m_dxrDevice->CreateStateObject(raytracingPipeline, IID_PPV_ARGS(&m_dxrStateObject)), L"Couldn't create DirectX Raytracing state object.\n");
A note about the maximum recursion depth is that this value is the absolute maximum value that you can call the TraceRay() function, and the shaders won’t stop the recursion for you at this depth, you need to handle this in your shaders. If you don’t handle this, you will get a hanged GPU, which results in a device lost error.
Calculating Shader Offset For Each Intersected Object
As you see we defined every shader that we will use in one pipeline and we will use this pipeline for every object in the scene. The reason behind it is that in ray tracing we won’t issue any draw calls for the objects, we will just dispatch rays to the scene and every intersection needs to call the related shader. This calculation is handled by our application and we can define it from multiple locationn, geometry datas for bottom level acceleration structures, instance datas for top level acceleration structures, and as a parameter of the TraceRay() function.
We can think the shader tables as a continuous memory block that holds the shader pointers for the objects in the scene. For each intersection the hit group index will be calculated with the below equation.
hitGroupPointer = &hitGroups[0] + (hitGroupStride * (RayTypeOffset + RayTypeStride * GeometryId + InstanceOffset))
This calculation is done by the DXR API, and quite hard to figure out by yourself, after tackling every variable with a slight resemblance, I found a introduction to this topic in a blog post by Will Usher. The post explains this calculation in depth, and compares the ray tracing frameworks of DXR, OptiX and Vulkan.
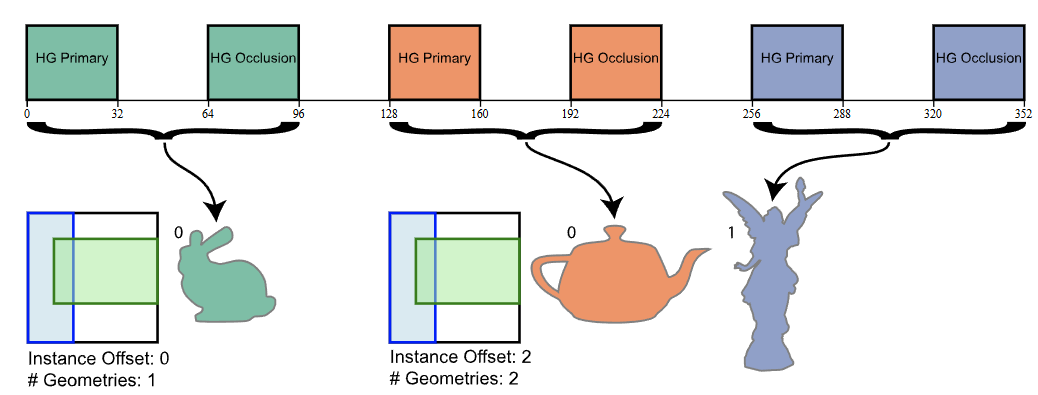
Figure taken from Will Usher's blog, showing a shader binding table with two instances, the second instance having two different geometries with different values for shader indices
Creating Acceleration Structures
Creating the acceleration structures is a straightforward process, we need to create the bottom level acceleration structures for the geometries in the scene, and the top level acceleration structures for the instances in the scene.
First we need to determine the memory cost of the structures, and create the scratch and result buffers for the build process. I created a bottom level acceleration structure for each geometry in the scene, and a top level acceleration structure for each instance in the scene.
std::vector<D3D12_BUILD_RAYTRACING_ACCELERATION_STRUCTURE_DESC> bottomLevelBuildDescs;
std::vector<ComPtr<ID3D12Resource>> scratchResources;
//get meshes
auto meshes = loader.GetMeshes();
for (size_t i = 0; i < meshes.size(); i++) {
D3D12_RAYTRACING_GEOMETRY_DESC geometryDesc = {};
geometryDesc.Type = D3D12_RAYTRACING_GEOMETRY_TYPE_TRIANGLES;
geometryDesc.Triangles.IndexBuffer = m_indexBuffer.resource->GetGPUVirtualAddress() + meshes[i].indexOffset * sizeof(Index);
geometryDesc.Triangles.IndexCount = meshes[i].indices.size();
geometryDesc.Triangles.IndexFormat = DXGI_FORMAT_R16_UINT;
geometryDesc.Triangles.Transform3x4 = 0; //if we have transform matrix for the geometry
geometryDesc.Triangles.VertexFormat = DXGI_FORMAT_R32G32B32_FLOAT;
geometryDesc.Triangles.VertexCount = meshes[i].vertices.size();
geometryDesc.Triangles.VertexBuffer.StartAddress = m_vertexBuffer.resource->GetGPUVirtualAddress() + meshes[i].vertexOffset * sizeof(Vertex);
geometryDesc.Triangles.VertexBuffer.StrideInBytes = sizeof(Vertex);
geometryDesc.Flags = D3D12_RAYTRACING_GEOMETRY_FLAG_OPAQUE;
D3D12_BUILD_RAYTRACING_ACCELERATION_STRUCTURE_DESC bottomLevelBuildDesc = {};
D3D12_BUILD_RAYTRACING_ACCELERATION_STRUCTURE_INPUTS &bottomLevelInputs = bottomLevelBuildDesc.Inputs;
bottomLevelInputs.DescsLayout = D3D12_ELEMENTS_LAYOUT_ARRAY;
bottomLevelInputs.Flags = D3D12_RAYTRACING_ACCELERATION_STRUCTURE_BUILD_FLAG_PREFER_FAST_TRACE;
bottomLevelInputs.NumDescs = 1;
bottomLevelInputs.Type = D3D12_RAYTRACING_ACCELERATION_STRUCTURE_TYPE_BOTTOM_LEVEL;
bottomLevelInputs.pGeometryDescs = &geometryDesc;
//we can get the prebuild info for the acceleration structure, which helps us to determine the memory cost of the structure
D3D12_RAYTRACING_ACCELERATION_STRUCTURE_PREBUILD_INFO bottomLevelPrebuildInfo = {};
m_dxrDevice->GetRaytracingAccelerationStructurePrebuildInfo(&bottomLevelInputs, &bottomLevelPrebuildInfo);
ThrowIfFalse(bottomLevelPrebuildInfo.ResultDataMaxSizeInBytes > 0);
//we will create a scratch buffer for each bottom level acceleration structure, and a result buffer for each bottom level acceleration structure
ComPtr<ID3D12Resource> scratchResource;
AllocateUAVBuffer(device, bottomLevelPrebuildInfo.ScratchDataSizeInBytes, &scratchResource, D3D12_RESOURCE_STATE_COMMON, L"ScratchResource");
scratchResources.push_back(scratchResource);
ComPtr<ID3D12Resource> m_bottomLevelAccelerationStructure;
D3D12_RESOURCE_STATES initialResourceState = D3D12_RESOURCE_STATE_RAYTRACING_ACCELERATION_STRUCTURE;
AllocateUAVBuffer(device, bottomLevelPrebuildInfo.ResultDataMaxSizeInBytes, &m_bottomLevelAccelerationStructure, initialResourceState, L"BottomLevelAccelerationStructure");
bottomLevelBuildDesc.ScratchAccelerationStructureData = scratchResource->GetGPUVirtualAddress();
bottomLevelBuildDesc.DestAccelerationStructureData = m_bottomLevelAccelerationStructure->GetGPUVirtualAddress();
m_bottomLevelAccelerationStructures.push_back(m_bottomLevelAccelerationStructure);
//the build process is done on the gpu so we need a command list and respected barriers for the build process
m_dxrCommandList.Get()->BuildRaytracingAccelerationStructure(&bottomLevelBuildDesc, 0, nullptr);
m_dxrCommandList.Get()->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::UAV(m_bottomLevelAccelerationStructure.Get()));
};
D3D12_RAYTRACING_ACCELERATION_STRUCTURE_BUILD_FLAGS buildFlags = D3D12_RAYTRACING_ACCELERATION_STRUCTURE_BUILD_FLAG_PREFER_FAST_TRACE;
D3D12_BUILD_RAYTRACING_ACCELERATION_STRUCTURE_DESC topLevelBuildDesc = {};
D3D12_BUILD_RAYTRACING_ACCELERATION_STRUCTURE_INPUTS &topLevelInputs = topLevelBuildDesc.Inputs;
topLevelInputs.DescsLayout = D3D12_ELEMENTS_LAYOUT_ARRAY;
topLevelInputs.Flags = buildFlags;
topLevelInputs.NumDescs = m_bottomLevelAccelerationStructures.size();
topLevelInputs.pGeometryDescs = nullptr;
topLevelInputs.Type = D3D12_RAYTRACING_ACCELERATION_STRUCTURE_TYPE_TOP_LEVEL;
D3D12_RAYTRACING_ACCELERATION_STRUCTURE_PREBUILD_INFO topLevelPrebuildInfo = {};
m_dxrDevice->GetRaytracingAccelerationStructurePrebuildInfo(&topLevelInputs, &topLevelPrebuildInfo);
ThrowIfFalse(topLevelPrebuildInfo.ResultDataMaxSizeInBytes > 0);
ComPtr<ID3D12Resource> scratchResource;
AllocateUAVBuffer(device, topLevelPrebuildInfo.ScratchDataSizeInBytes, &scratchResource, D3D12_RESOURCE_STATE_COMMON, L"ScratchResource");
{
D3D12_RESOURCE_STATES initialResourceState = D3D12_RESOURCE_STATE_RAYTRACING_ACCELERATION_STRUCTURE;
AllocateUAVBuffer(device, topLevelPrebuildInfo.ResultDataMaxSizeInBytes, &m_topLevelAccelerationStructure, initialResourceState, L"TopLevelAccelerationStructure");
}
// Create an instance desc for the bottom-level acceleration structure.
ComPtr<ID3D12Resource> instanceDescsRes;
std::vector<D3D12_RAYTRACING_INSTANCE_DESC> instanceDescs;
for (size_t i = 0; i < meshes.size(); i++) {
//check wheter mesh is transparent or not
auto mat = loader.GetMaterials()[meshes[i].materialId];
bool isTransparent = mat.dissolve < 1.0f;
D3D12_RAYTRACING_INSTANCE_DESC instanceDesc = {};
instanceDesc.InstanceID = static_cast<UINT>(i);
instanceDesc.InstanceContributionToHitGroupIndex = isTransparent ? 1 : 0; // This is the deciding factor for our hit groups, we have 2
instanceDesc.InstanceMask = 1;
instanceDesc.Flags = D3D12_RAYTRACING_INSTANCE_FLAG_NONE;
instanceDesc.AccelerationStructure = m_bottomLevelAccelerationStructures[i]->GetGPUVirtualAddress();
instanceDesc.Transform[0][0] = 1;
instanceDesc.Transform[1][1] = 1;
instanceDesc.Transform[2][2] = 1;
instanceDescs.push_back(instanceDesc);
}
AllocateUploadBuffer(device, instanceDescs.data(), instanceDescs.size() * sizeof(D3D12_RAYTRACING_INSTANCE_DESC), &instanceDescsRes, L"InstanceDescs");
// Top Level Acceleration Structure desc
{
topLevelBuildDesc.DestAccelerationStructureData = m_topLevelAccelerationStructure->GetGPUVirtualAddress();
topLevelBuildDesc.ScratchAccelerationStructureData = scratchResource->GetGPUVirtualAddress();
topLevelBuildDesc.Inputs.InstanceDescs = instanceDescsRes->GetGPUVirtualAddress();
}
m_dxrCommandList.Get()->BuildRaytracingAccelerationStructure(&topLevelBuildDesc, 0, nullptr);
// Kick off acceleration structure construction.
m_deviceResources->ExecuteCommandList();
// Wait for GPU to finish as the locally created temporary GPU resources will get released once we go out of scope.
m_deviceResources->WaitForGpu();
Multi Mesh Bottom Level Structures
In the above code, I created a bottom level acceleration structure for each mesh in the scene, and a top level acceleration structure for each instance in the scene. This is a good starting point for a simple scene, but for a more complex scene, we can group multiple geometries in a single bottom level acceleration structure. This will reduce the memory cost of the acceleration structures, and the build time of the structures, and if we are sure that these meshes will near each other in the scene, we can reduce the number of intersection tests for the rays.
Passing Data to the GPU
After creating our pipeline and acceleration structures, we need to pass the necessary material data and instance datas to the GPU. I used a unbounded ByteAddressBuffer for the instance data, and we can load the structure from the HLSL with the instanceID.
struct InstanceData
{
XMFLOAT3 color;
float exponent;
XMFLOAT3 kd;
UINT brdfType;
XMFLOAT3 ks;
UINT vertexOffset;
UINT indexOffset;
UINT cdfOffset;
UINT triangleCount;
UINT is_emissive;
float totalArea;
XMFLOAT3 emission;
float dissolve;
};
ByteAddressBuffer InstanceDatas : register(t3, space0);
HLSL Buffer Alignment Issues With Arrays
For the scene data, I used constant buffers, and I encountered a problem with the alignment of the arrays in the constant buffer. I created a predefined maximum sized index array for the indices of the emissive meshes (this will help us to sample from them in the Next Event Estimation). However, when I run the code I noticed some errors with the indices.
struct SceneConstantBuffer
{
XMMATRIX projectionToWorld;
XMVECTOR cameraPosition;
XMVECTOR lightPosition;
XMVECTOR lightAmbientColor;
XMVECTOR lightDiffuseColor;
XMVECTOR random_floats;
float accumulative_frame_count;
UINT LightCount;
PAD_VAR; //4 byte padding variables
PAD_VAR;
UINT LightMeshIndices[16];
};
When I look into the specifications of the HLSL, I found that the arrays in the constant buffers are aligned to 16 bytes, and the size of the array is rounded up to the nearest multiple of 16 bytes. This means that if we have an array of 16 elements, the size of the array will be 16 * 16 = 256 bytes, and the next variable will be aligned to 16 bytes. This is a problem for us, because we need to pass the indices from the C++ code, and C++ alligns arrays packed with 4 bytes alignment for uints which are 4 bytes. When searching this issue I came across a website which shows the memory alignment differences between the C and HLSL, which helped me to solve and understand the problem.
As a solution I packed the uint’s into uint4 for HLSL and accessed with offsets in the HLSL code, I used the same definitions for compiling the HLSL structs in the C++ code so I used compiler definitions for the HLSL code.
#ifdef HLSL
uint4 LightMeshIndices[4];
#else
UINT LightMeshIndices[16];
#endif
Local and Global Root Arguments
In the ray tracing pipeline, we can define two types of root arguments, local and global. Local root arguments are the data that will be passed to the shaders for each intersection, and global root arguments are the data that will be shared across the shaders. In this example I didn’t use the local root arguments, but I used the global root arguments for the scene data and the instance data, defining the root arguments are the same process as without DXR, so I will skip this part.
Ray Generation
To start the ray tracing process, we need to call DispatchRays() function with the ray generation shader index. This function will start the ray tracing process and call the ray generation shader for each pixel in the screen. In the ray generation shader, we need to define the ray direction and origin, and call the TraceRay() function to start the ray tracing process.
auto DispatchRays = [&](auto* commandList, auto* stateObject, auto* dispatchDesc)
{
// Since each shader table has only one shader record, the stride is same as the size.
dispatchDesc->HitGroupTable.StartAddress = m_hitGroupShaderTable->GetGPUVirtualAddress(); // Hit group shader table which holds our 2 hit groups
dispatchDesc->HitGroupTable.SizeInBytes = m_hitGroupShaderTable->GetDesc().Width;
dispatchDesc->HitGroupTable.StrideInBytes = dispatchDesc->HitGroupTable.SizeInBytes / 2;
dispatchDesc->MissShaderTable.StartAddress = m_missShaderTable->GetGPUVirtualAddress();
dispatchDesc->MissShaderTable.SizeInBytes = m_missShaderTable->GetDesc().Width;
dispatchDesc->MissShaderTable.StrideInBytes = dispatchDesc->MissShaderTable.SizeInBytes;
dispatchDesc->RayGenerationShaderRecord.StartAddress = m_rayGenShaderTable->GetGPUVirtualAddress();
dispatchDesc->RayGenerationShaderRecord.SizeInBytes = m_rayGenShaderTable->GetDesc().Width;
dispatchDesc->Width = m_width;
dispatchDesc->Height = m_height;
dispatchDesc->Depth = 1;
commandList->SetPipelineState1(stateObject);
commandList->DispatchRays(dispatchDesc);
};
[shader("raygeneration")]
void MyRaygenShader()
{
float3 finalColor = float3(0, 0, 0);
uint sampleCount = 2; // Define the number of samples per pixel.
// Loop over the number of samples per pixel.
for (uint i = 0; i < sampleCount; ++i)
{
//generate sample offset using g_sceneCB.random_floats
float2 sampleOffset = float2(
g_sceneCB.random_floats[i],
g_sceneCB.random_floats[i + 1]
);
float3 rayDir;
float3 origin;
// Generate a ray for the current sample.
GenerateCameraRay(DispatchRaysIndex().xy, sampleOffset, origin, rayDir);
// Trace the ray.
RayDesc ray;
ray.Origin = origin;
ray.Direction = rayDir;
ray.TMin = 0.001; // Avoid aliasing issues.
ray.TMax = 10000.0; // Set maximum ray extent.
RayPayload payload = { float4(0, 0, 0, 0), 6, 0, 0, 0, 0};
payload.recursion_depth = 6;
payload.is_shadow_ray = 0;
payload.is_indirect_ray = 0;
payload.potential = 0.99f;
payload.distance = 0.0f;
TraceRay(Scene, RAY_FLAG_CULL_BACK_FACING_TRIANGLES, ~0, 0, 1, 0, ray, payload);
// Accumulate the result for this sample.
finalColor += payload.color.xyz;
}
// Average the accumulated color.
finalColor /= sampleCount;
// Write the raytraced color to the output texture.
float4 before = RenderTarget[DispatchRaysIndex().xy] * (g_sceneCB.accumulative_frame_count);
RenderTarget[DispatchRaysIndex().xy] = (before + float4(finalColor, 1.0f)) / (g_sceneCB.accumulative_frame_count + 1.0f);
RenderTarget[DispatchRaysIndex().xy].a = 1.0f;
}
In the ray generation shader, we need to define the ray directions and origins, we can calculate these with the camera matrices. And for accumulating the color values, we can use a UAV texture to hold the color values. However, in every camera movement we need to reset the frame count, so we can reset these color values to 0, and start acumulating the color values for the new frame.
inline void GenerateCameraRay(uint2 index, float2 sampleOffset, out float3 origin, out float3 direction)
{
float2 xy = index + sampleOffset; // Adjust pixel position by sample offset.
float2 screenPos = xy / DispatchRaysDimensions().xy * 2.0 - 1.0;
// Invert Y for DirectX-style coordinates.
screenPos.y = -screenPos.y;
// Unproject the pixel coordinate into a ray.
float4 world = mul(float4(screenPos, 0, 1), g_sceneCB.projectionToWorld);
world.xyz /= world.w;
origin = g_sceneCB.cameraPosition.xyz;
direction = normalize(world.xyz - origin);
}
Issues With Random Float Generation and Hash Functions
While sampling from the pixels, I need to uniformly sample the directions of the rays from inside the pixel, however in the GPU we don’t have a random number generator, so we can use hashing functions to generate random numbers, I found some shaders online, however to improve the randomness of the numbers, in each frame I generated 4 random floats in CPU and passed them to the GPU, and used these random numbers for the sampling, this helped me to get rid of the aliasing issues in the image.
float hash(float3 p) {
return frac(sin(dot(p, float3(12.9898, 78.233, 45.164))) * 43758.5453123);
}
float2 random2D(float3 seed) {
return float2(hash(seed), hash(seed + float3(1.0, 0.0, 0.0)));
}
Closest Hit Shaders
I will introduce the closest hit shaders for the diffuse one step by step with some optimization techniques I used in the CPU version of the path tracer.
[shader("closesthit")]
void MyClosestHitShader(inout RayPayload payload, in MyAttributes attr)
{
payload.recursion_depth--;
if(payload.recursion_depth <= 0) // To avoid device hang
{
return;
}
InstanceData i = InstanceDatas.Load < InstanceData > (sizeof(InstanceData) * InstanceID()); // load the instance data for the intersection
float3 hitPosition = HitWorldPosition();
// Get the base index of the triangle's first 16 bit index.
uint indexSizeInBytes = 2;
uint indicesPerTriangle = 3;
uint triangleIndexStride = indicesPerTriangle * indexSizeInBytes;
uint baseIndex = (i.indexOffset * indexSizeInBytes) + PrimitiveIndex() * triangleIndexStride;
// Load up 3 16 bit indices for the triangle.
const uint3 indices = Load3x16BitIndices(baseIndex);
// Retrieve corresponding vertex normals for the triangle vertices.
float3 vertexNormals[3] = {
Vertices[i.vertexOffset + indices[0]].normal,
Vertices[i.vertexOffset + indices[1]].normal,
Vertices[i.vertexOffset + indices[2]].normal
};
float3 vertexPositions[3] = {
Vertices[i.vertexOffset + indices[0]].position,
Vertices[i.vertexOffset + indices[1]].position,
Vertices[i.vertexOffset + indices[2]].position
};
// Compute the triangle's normal.
float3 triangleNormal = HitAttribute(vertexNormals, attr);
float3 trianglePosition = HitAttribute(vertexPositions, attr);
payload.distance = length(hitPosition - WorldRayOrigin()); // this will help us to calculate the distance to the hit point, which will be useful for beer's law
// Emissive contribution
if (i.is_emissive > 0) {
payload.color = float4(i.emission, 1.0f); // Directly add emissive color to payload
return; // Stop further processing since the surface emits light
}
// Phong BRDF constants
const float shininess = 200.0f; // Shininess for specular highlight
const float3 baseColor = i.color; // Base color from instance data
float factor = 1.0f;
float3 kd = i.diffuse;
float max_diffuse = max(kd.r, max(kd.g, kd.b));
float potential = payload.potential * max_diffuse;
potential = clamp(potential, 0.0f, 0.99f);
// Trace each scattered ray and accumulate radiance
RayDesc scatterRay;
scatterRay.Origin = hitPosition + triangleNormal * 0.001; // Offset to avoid self-intersection
scatterRay.Direction = scatterDirection;
scatterRay.TMin = 0.001;
scatterRay.TMax = 1e6;
RayPayload scatterPayload;
scatterPayload.color = float4(0, 0, 0, 0); // Initialize scatter payload color
scatterPayload.recursion_depth = payload.recursion_depth;
scatterPayload.is_shadow_ray = 0;
scatterPayload.is_indirect_ray = 1;
scatterPayload.potential = potential;
TraceRay(Scene, RAY_FLAG_NONE, ~0, 0, 1, 0, scatterRay, scatterPayload);
float3 wi = normalize(scatterRay.Direction);
float3 intensity = scatterPayload.color.xyz;
float3 w0 = -normalize(WorldRayDirection());
float cost = max(0.0, dot(wi, triangleNormal));
float3 kd = i.diffuse;
float3 ks = i.specular;
float3 reflected = reflect(-wi, triangleNormal);
float cosa = max(0.0, dot(w0, reflected));
float pw = pow(cosa, shininess);
float3 brdf = (kd * (1.0f / pi)) + (ks * ((shininess + 2.0f) / (2.0f * pi)) * (pw));
accumulatedColor += (intensity * brdf * pi) * factor; // Divide by 3 to average contributions
payload.color = float4(accumulatedColor / (float)splitting_factor, 1.0f) + float4(nee_light_sample, 0.0f); // Add accumulated color to the payload
return;
}
Importance Sampling
To sample the directions of the rays, we can use importance sampling, which will help us to sample the directions of the rays with the probability of the directions. In the above code, I used the cosine weighted hemisphere sampling for the diffuse materials.
float3 CreateNonColinearVector(float3 normal) {
// Choose a vector that is not colinear with the normal
float3 nonColinearVector;
if (abs(normal.x) < abs(normal.y) && abs(normal.x) < abs(normal.z)) {
nonColinearVector = float3(1.0, 0.0, 0.0);
} else if (abs(normal.y) < abs(normal.z)) {
nonColinearVector = float3(0.0, 1.0, 0.0);
} else {
nonColinearVector = float3(0.0, 0.0, 1.0);
}
return nonColinearVector;
}
float3 randomInHemisphere(float3 normal, float3 seed) {
float2 rand = random2D(seed);
float r1 = rand.x;
float r2 = rand.y;
float3 r = normal;
float3 rp = CreateNonColinearVector(r);
float3 u = normalize(cross(r, rp));
float3 v = normalize(cross(r, u));
float3 uu = u * sqrt(r2) * cos(2.0f * pi * r1);
float3 vv = v * sqrt(r2) * sin(2.0f * pi * r1);
float3 nn = r * sqrt(1.0f - r2);
return normalize(uu + vv + nn);
}
Shadow Ray Hack
For shadow rays, I used the color values and a uint value to determine a shadow ray in the RayPayload to determine the shadow rays. This is a hacky way to determine the shadow rays, and I will implement a more efficient way to determine the shadow rays with any hit shaders in the future.
if (payload.is_shadow_ray == 1)
{
InstanceData i = InstanceDatas.Load < InstanceData > (sizeof(InstanceData) * InstanceID());
if(i.is_emissive > 0) //emissive materials don't cause shadows
{
payload.color = float4(0,0,0,0);
return;
}
payload.color = float4(1.0f, 1.0f, 1.0f, 1.0f);
return;
}
Next Event Estimation
For next event estimation, we need to sample from the emissive meshes. While building the geometry data in the CPU code, I created the CDF for all the meshes, and passed this data in a ByteAddressBuffer to the GPU. In the closest hit shader, I used the CDF to sample from the emissive meshes, with every instance data has an offset to this CDF array.
ByteAddressBuffer CDFBuffer : register(t4, space0);
float3 SamplePointOnMesh(in InstanceData mesh, in float3 seed)
{
uint triangleCount = mesh.triangleCount;
float2 rand = random2D(seed);
float cdf_random = hash(rand.x * rand.y * 23.23243f);
for(uint i = 0; i < triangleCount; i++)
{
float cdf = CDFBuffer.Load <float> ((mesh.cdfOffset * 4) + i * 4);
if(cdf_random <= cdf)
uint i = (float)triangleCount * rand;
{
//uint index = i * 3;
uint3 indices = Load3x16BitIndices((mesh.indexOffset * 2) + i * 3 * 2);
float3 v0 = Vertices[indices.x + mesh.vertexOffset].position;
float3 v1 = Vertices[indices.y + mesh.vertexOffset].position;
float3 v2 = Vertices[indices.z + mesh.vertexOffset].position;
return v0 * (1.0f - sqrt(rand.x)) + v1 * (sqrt(rand.x) * (1.0f - rand.y)) + v2 * (rand.y * sqrt(rand.x));
}
}
}
The lighting calculations is same with a diffuse ray, calculated in each intersection, so I will skip that part. However, there is an important point to consider, which is when we are using next event estimation we need to not sample the emissive meshes with the random scattered rays. I solved this by adding a indirect ray flag to payload to determine the rays are scattered or not.
// Emissive contribution
if (i.is_emissive > 0) {
if(payload.is_indirect_ray > 0) //for Next Event Estimation
{
return;
}
payload.color = float4(i.emission, 1.0f); // Directly add emissive color to payload
return; // Stop further processing since the surface emits light
}
This code worked well for meshes with small triangle counts, however for the meshes with slightly larger triangle counts (4000 triangles), the CDF sampling was so slow that it tanked the FPS values. When rendering these meshes I assumed equal area for each triangle, and calculated the index directly from a random value.
Splitting
Splitting is easy to implement, the important thing in the splitting is to make sure that every scatter direction from the intersection is different from each other.
// Generate three random directions for scattering
float3 scatterDirections[splitting_factor];
for (int j = 0; j < splitting_factor; j++) {
scatterDirections[j] = randomInHemisphere(triangleNormal, float3(hitPosition + triangleNormal * j * 4.33253f));
}
Russian Roulette
The russian roulette is a technique to terminate the rays with a probability, this will help us to reduce the number of rays in the scene, which helped tremendously to increase the FPS values of the scene with 4x increase. I used the diffuse component of the material to determine the probability of the russian roulette, and passed a throughput value to accumulate the probabilities of the russian roulette.
{
if (hash(g_sceneCB.random_floats[1] * (hitPosition.x + hitPosition.y + hitPosition.z) + 0.234354f + triangleNormal.y) > potential)
{
payload.color += float4(nee_light_sample, 0.0f); // Add accumulated color to the payload
return;
}
else
{
factor = 1.0f / (potential); //factor to multiply the result if the ray is not killed
}
}
Miss Shaders
Miss shader is a basic implementation in my case as I don’t have any skybox or environment map, I just return a black color for the miss shader.
[shader("miss")]
void MyMissShader(inout RayPayload payload)
{
float4 background = float4(0.0f, 0.0f, 0.0f, 0.0f);
payload.color = background;
}
Future Optimizations for Real Time Rendering
The future of this project will include the optimization points with the DXR API, and the memory optimizations for the acceleration structures. After having a solid foundation for the ray tracing pipeline, I will try to implement more complex techniques for reducing the noise in the scene.
Results

Final result of the ray tracer
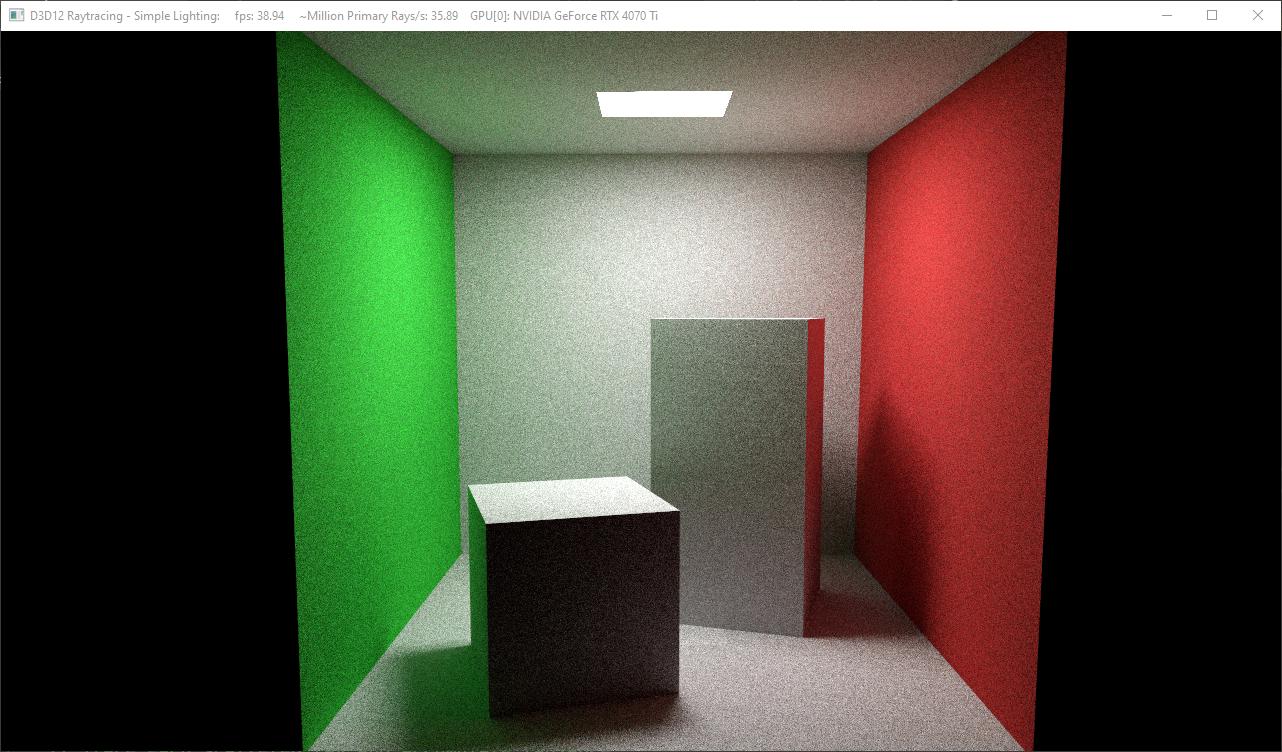

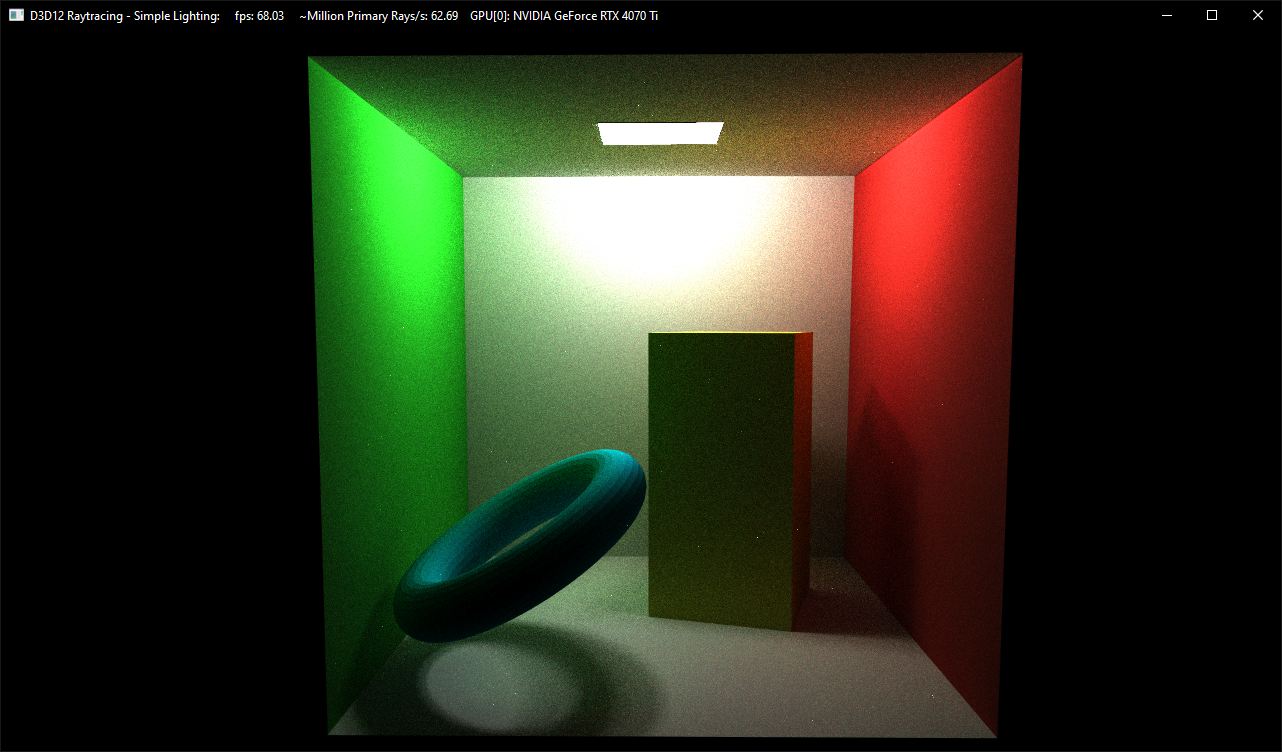
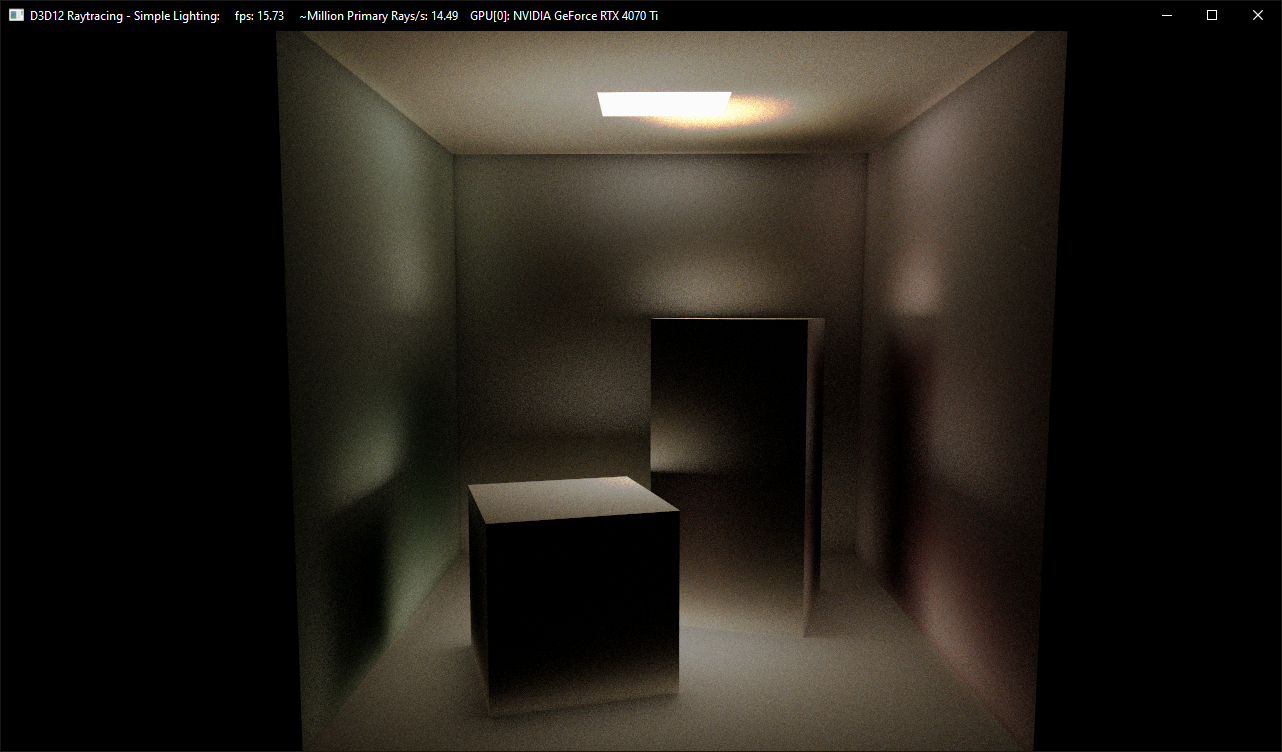
Buggy result from the initial try
Videos
References
Ahmet Oğuz Akyüz, Lecture Slides from CENG795 Advanced Ray Tracing, Middle East Technical University
Will Usher, The RTX Shader Binding Table, https://www.willusher.io/graphics/2019/11/20/the-sbt-three-ways/
Chris Wyman, Peter Shirley, Colin Barré-Brisebois, ACM SIGGRAPH 2018 Courses, Introduction to DirectX RayTracing https://intro-to-dxr.cwyman.org
Shawn Hargreaves, Introduction to DirectX Raytracing, Part 2 - The API https://intro-to-dxr.cwyman.org/presentations/IntroDXR_RaytracingAPI.pdf
Seppe Dekeyser, Rendering Pixels, Getting Started with DirectX Raytracing https://renderingpixels.com/2022/07/getting-started-with-directx-raytracing/